
1月20日下午,X开源了最新的推荐算法。
马斯克评论道:“我们知道这个算法很愚蠢,仍然需要重大改进,但至少你可以看到我们正在努力实时改进它。其他社交平台不敢这样做。”
他的说法有两点。首先,他承认该算法的缺点。其次,他将透明度作为一个关键卖点。
这是X第二次开源其算法。 2023 版本已经三年没有更新,并且已经与生产系统断开连接。这一次,代码库被完全重写。核心模型从传统机器学习转向 Grok Transformer。据官方描述,“手动特征工程已被完全淘汰。”
简单来说:之前的算法都是靠工程师手动调整参数。现在,人工智能直接分析您的互动历史记录,以决定是否推广您的内容。
对于内容创作者来说,这意味着“最佳发布时间”或“哪些标签吸引关注者”等策略可能不再有效。
我们还审查了开源 GitHub 存储库,并在 AI 的帮助下,在代码中发现了一些值得探索的硬编码逻辑。
算法逻辑转变:从人工规则到AI驱动判断
首先,让我们澄清一下新旧版本之间的差异,以避免在接下来的讨论中造成混乱。
2023年,Twitter的开源算法被称为HeavyRanker。从根本上来说,这是传统的机器学习。工程师手动定义了数百个功能:帖子是否包含图像、作者的关注者数量、发布时间、是否包含链接等等。
每个功能都分配了一个权重,并不断调整权重以找到最有效的组合。
这个新的开源版本称为 Phoenix。它的架构完全不同——可以将其视为一种更加依赖于大型人工智能模型的算法。核心使用 Grok 变压器,与 ChatGPT 和 Claude 背后的技术相同。
官方自述文件很清楚:“我们已经消除了每一个手工设计的功能。”
依赖于手动提取内容特征的旧的基于规则的系统已经完全消失。
那么,算法是用什么来判断内容好坏的呢?
答案:你的行为顺序。你喜欢什么,你回复过谁,你在哪些帖子上停留了超过两分钟,你屏蔽了哪些类型的帐户。 Phoenix 将这些行为提供给转换器,让模型学习并总结模式。
举例来说:旧算法就像手动创建的记分卡,为每个复选框分配分数。
新算法就像人工智能一样,可以访问您的整个浏览历史记录,预测您接下来想要看到的内容。
对于创作者来说,这意味着两件事:
首先,“最佳发布时间”或“黄金标签”等策略现在的价值要低得多。该模型不再着眼于固定特征,而是着眼于每个用户的个人喜好。
其次,你的内容是否得到推广更多地取决于“用户对你的内容的反应”。这些反应被量化为 15 种行为预测,我们接下来将详细介绍。
算法预测 15 种用户反应
当 Phoenix 评估推荐帖子时,它会预测 15 种可能的用户操作:
- 积极行动:点赞、回复、转发、引用转发、点击帖子、点击作者个人资料、观看超过一半的视频、展开图片、分享、停留一定时间、关注作者
- 负面操作:选择“不感兴趣”、屏蔽作者、将作者静音、举报
每个动作都有一个预测概率。例如,该模型可能会估计您喜欢某个帖子的可能性为 60%,而您屏蔽该帖子的可能性为 5%。
然后,算法将每个概率乘以其相应的权重,并将它们相加以获得最终分数。
公式为:
最终得分 = Σ ( 体重 × P(动作) )
积极的行动具有积极的权重;负面行为具有负面权重。
总分越高的帖子排名越高;分数较低的被推低。
实际上,内容是否“好”不再仅由其内在质量决定(尽管可读性和价值仍然是共享的先决条件)。相反,它是由“你的内容引起的反应”决定的。该算法不关心内容本身;它关心用户行为。
按照这种逻辑,在极端情况下,触发大量回复的低质量帖子可能会比没有参与度的高质量帖子得分更高。这可能就是系统的底层逻辑。
但是,新的开源算法并未披露每种行为的确切权重,但 2023 年版本却披露了。
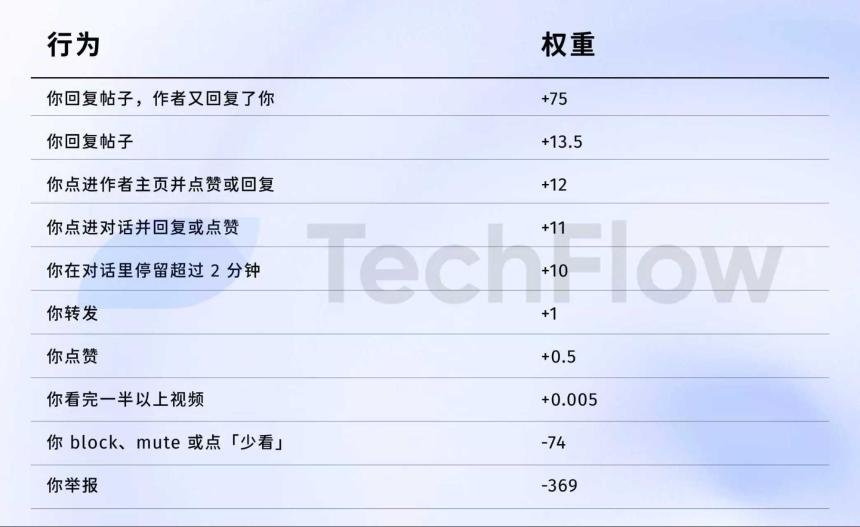
旧版本参考:一份报告 = 738 个赞
让我们看一下 2023 年的数据集。虽然它已经过时,但它有助于说明算法如何评估不同的操作。
2023年4月5日,X在GitHub上公开发布了一组权重数据。
以下是数字:

说白了:
数据来源:旧版本GitHub twitter/the-algorithm-ml存储库。点击查看原始算法。
有几个数字值得注意:
首先,点赞几乎毫无价值。权重仅为0.5,是积极行动中最低的。该算法认为“点赞”几乎毫无价值。
其次,对话才是最重要的。 “你回复,作者也回复”的权重是点赞的75—150倍。该算法对双向对话的重视远远超过简单的点赞。
第三,负面反馈会带来严重的惩罚。 1 个阻止或静音 (-74) 需要 148 个点赞才能抵消。一份报告 (-369) 需要 738 个赞。这些负面分数会累积在您帐户的声誉中,影响未来的帖子分发。
第四,视频完成率权重极低,仅为0.005,几乎可以忽略不计。这与 TikTok 等平台形成鲜明对比,后者将完成率视为核心指标。
官方文件还指出:“文件中的确切权重可以随时调整……此后,我们定期调整权重以针对平台指标进行优化。”
权重可以随时更改——而且确实如此。
新版本没有透露具体数值,但README中的逻辑框架是一样的:积极行为加分,消极行为减分,最终得分是加权和。
确切的数字可能会发生变化,但相对顺序可能不会改变。回复别人的评论比获得 100 个赞更有价值。被屏蔽比根本没有互动更糟糕。
创作者应该如何处理这些信息?
在审查了新旧 Twitter 算法代码后,以下是一些可操作的要点:
1.回复您的评论者。在权重表中,“作者回复评论者”是得分最高的动作(+75),比点赞有价值 150 倍。您不需要征求评论,但如果有人发表评论,请务必回复——即使是简单的“谢谢”也会被算法计算在内。
2.避免让用户想要阻止您。 1 个区块需要 148 个点赞才能抵消。有争议的内容可能会提高参与度,但如果该参与度是“这个人很烦人,请阻止”,那么您帐户的声誉将受到长期打击,影响所有未来的帖子分发。争议是一把双刃剑——挑衅之前请三思。
3.在评论中添加外部链接。该算法不希望用户离开平台。在正文中包含链接将受到处罚——马斯克已公开证实了这一点。如果您想增加流量,请将主要内容放在帖子中,并将链接放在第一条评论中。
4.不要发送垃圾邮件。新代码包括一个作者多样性评分器,它会惩罚同一作者的连续帖子。目的是使用户的信息流多样化,因此最好发布一篇高质量的文章,而不是连续发布十篇。
6.不再有“最佳发布时间”。旧的算法使用“发布时间”作为手动特征,但 Phoenix 已经取消了它。 Phoenix只看用户行为,不看发帖时间。所以那些“星期二下午 3 点”。策略的相关性比以往任何时候都低。
这些是可以从代码中收集到的内容。
X 的公共文档中还存在本开源版本中没有的奖励和惩罚规则:蓝色检查验证可提高覆盖范围,全大写帖子将受到处罚,敏感内容会导致覆盖范围减少 80%。这些规则不是开源的,因此这里不进行介绍。
总的来说,这个开源版本意义重大。
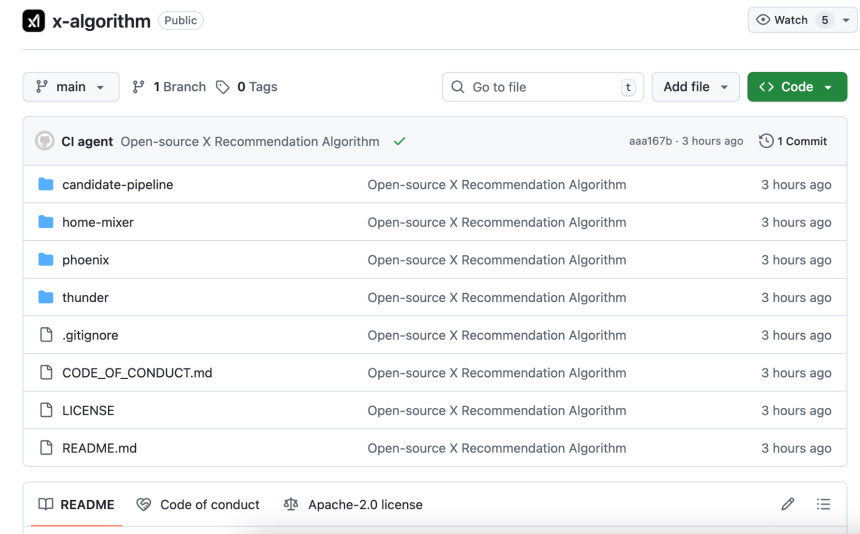
完整的系统架构、候选内容回忆逻辑、评分和排名过程以及各种过滤器都包含在内。代码主要是Rust和Python,结构清晰,README比很多商业项目更详细。
但是,缺少一些关键要素。
1.权重参数不公开。该代码仅解释了“积极行为加分,消极行为减分”,但没有具体说明点赞或屏蔽的价值。 2023年版本至少披露了数字;这次只有公式框架可用。
2.模型权重不公开。 Phoenix 使用 Grok 变压器,但不包括模型参数。您可以看到模型的调用方式,但看不到其内部工作原理。
3.训练数据不公开。目前尚不清楚使用哪些数据来训练模型,如何对用户行为进行采样,或者如何构建正样本和负样本。
换句话说,这个开源版本告诉您“我们使用加权和来计算分数”,但不是实际的权重;它告诉您“我们使用变压器来预测行为概率”,但没有告诉您变压器的内部结构。
相比之下,TikTok 和 Instagram 的发布量还没有那么多。 X的开源版本确实比其他主要平台更全面,但仍然不完全透明。
这并不意味着开源没有价值。对于创作者和研究人员来说,能够查看代码比根本无法访问要好。